Parallel Execution
Drastically reduce processing time with simultaneous agent execution
Execute steps in parallel to improve overall workflow efficiency. Process independent tasks by different agents simultaneously, dramatically accelerating complex operations.
Basic Principle
Parallel processing only activates when explicitly requested by the user. If no parallel intent is detected, sequential execution is used.
When to Use Parallel
- 1."Do simultaneously" expressions
- 2."In parallel" expressions
- 3."All at once" expressions
When to Use Sequential
- 1.No explicit parallel request
- 2."Do X then do Y" sequential orders
- 3.Simple tasks with minimal parallelization benefit
Samples
Sample 1: Slack + Discord
Watch simultaneous posting to Slack and Discord. Information is distributed in parallel across different communication platforms for efficient multi-platform operations.
- Simultaneous access to different services
- Significant reduction in processing time
- Automatic result integration
Sample 2: Devin + Cursor
An example of parallelizing Devin and Cursor to accelerate development tasks. Different AI development tools simultaneously generate and review code, maximizing development efficiency.
Execution Result: Cursor and Devin processing tasks simultaneously
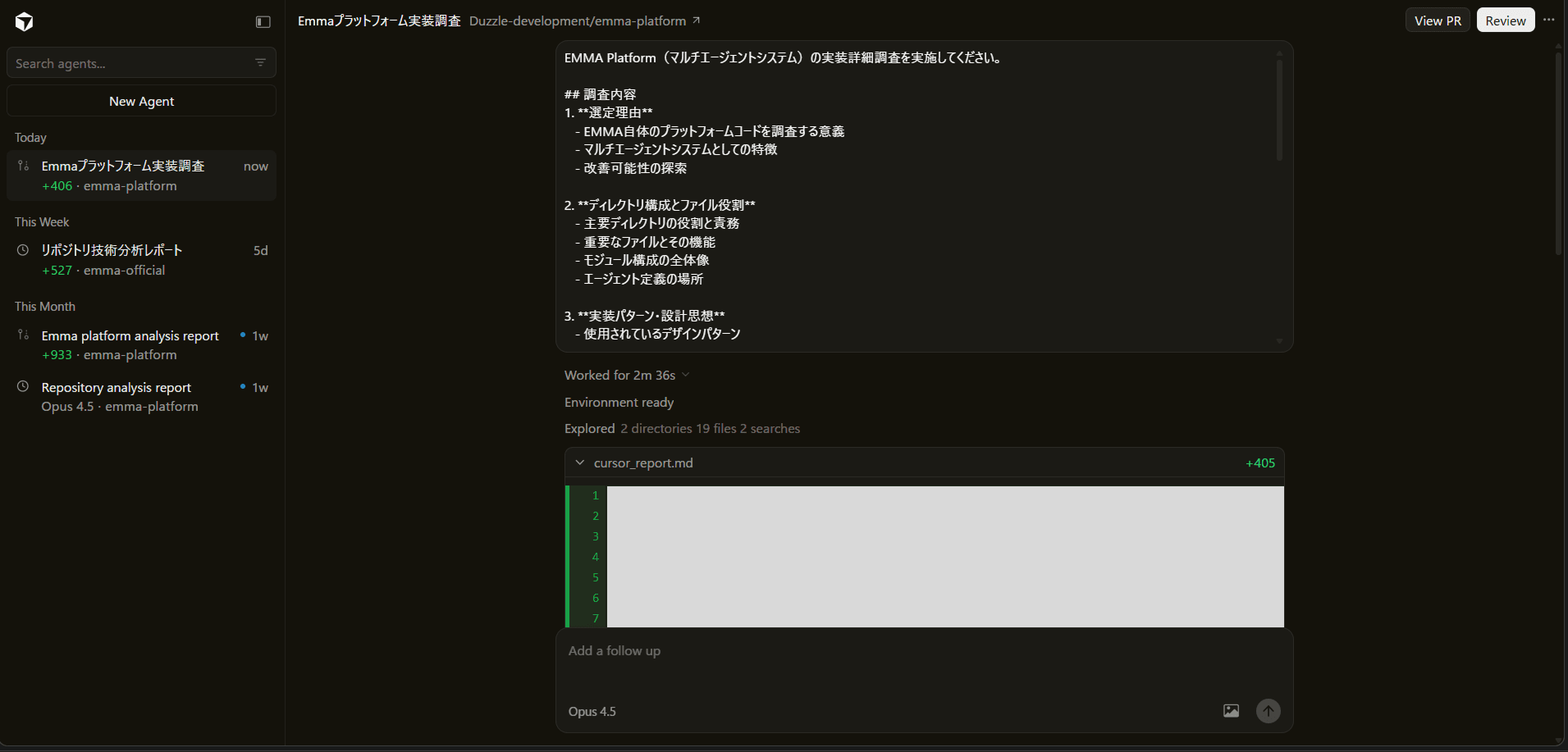
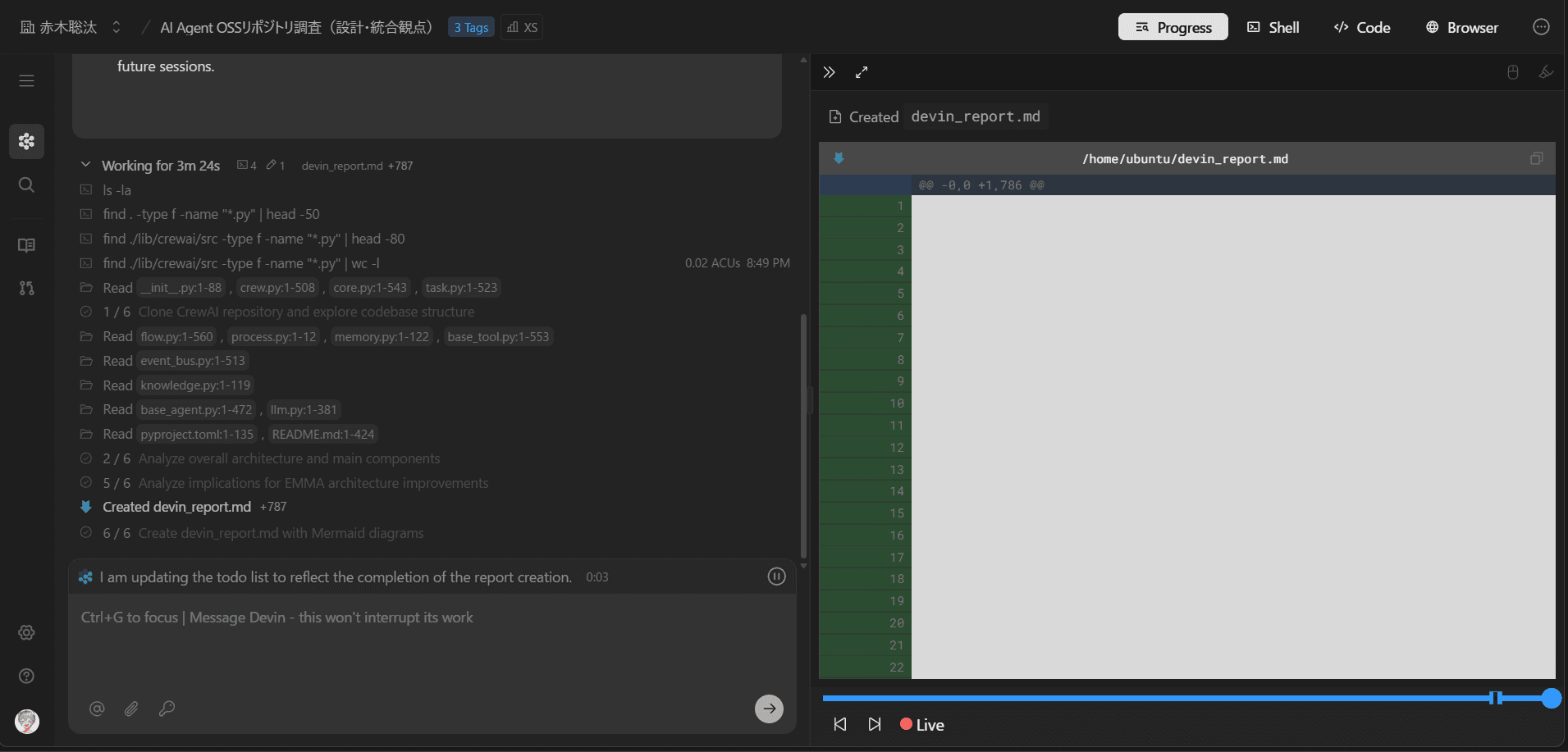
- Parallel utilization of AI development tools
- Simultaneous code generation and review
- Shortened development cycle
Sample 3: Researcher + Browser
An example of parallelizing Researcher and Browser to accelerate research tasks. While Researcher analyzes information, Browser simultaneously collects data from multiple web sources.
Execution Result: Researcher and Browser processing tasks simultaneously
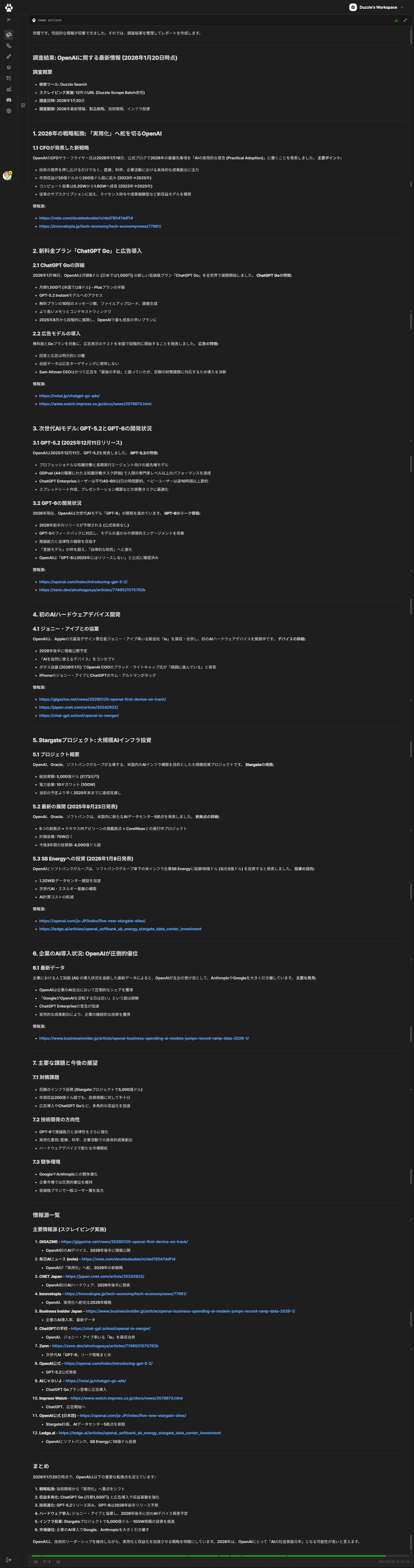
- Simultaneous information gathering from multiple sources
- Parallel processing of research and analysis
- Significant reduction in research time
Best Practices for Parallel Execution
While emma theoretically supports n-way parallelism (unlimited parallel execution), we recommend 2-3 agents in parallel for production use. Excessive parallelization increases the risk of resource contention and API rate limits, potentially degrading performance.